前言
在之前写的《利用机器学习分析vmp的思路》中,把读写内存的操作数直接替换成了绝对地址的形式,这就产生了大量赋值语句,阅读起来也不是很友好。写这篇文章的主要目的是如何做进一步的优化,本篇文章用到了程序切片技术和编译原理中的一些优化算法,复制传播、死代码删除和有向无环图DAG的局部优化。
trace的处理
在之前写的文章基础上对trace增加了eflags寄存器的记录。利用程序切片技术提取了handle与写内存相关的指令后,通过一些简单的特征就可以处理该样本trace中所有的handle,所以本篇没有使用深度学习的方法对handle进行分类处理,深度学习也只是通过有标签的handle数据集代替了人工提取特征的过程。
trace处理后会得到以下文件:
图片1.png
NormalCode表示正常的代码,不需要对其优化处理,VmProcedureCode表示虚拟机中执行的代码,后面的数字表示执行的顺序。handle的识别和处理参考相应的代码
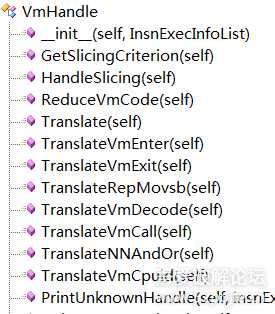
图片2.png
复制传播
复制传播(Copy Propagation)的思想:对于给定的关于某个变量v和s的赋值v=s,在没有出现其他关于v定值的程序范围内,可以用s来替代出现的v的引用。
handle处理后,trace中含有大量的mov语句,可以利用复制传播配合死代码消除处理掉冗余的mov语句。
比如有以下指令序列:
b=ac=bd=c按照复制传播的思想,c可以用a代替,即d=a。如果c是不活跃的,那么c=b是可以删除的。
复制传播可以通过ud链(Use-Definition Chains)实现,ud链描述的是指令或语句中引用的变量可能定值点的位置。因为在很多情况下,一个定值是否能实际到达某一特定程序点是不可判定的,有时候需要依赖于特定的外部输入。当然,在trace中可以直接认为都是可到达的。ud链的构造可以通过到达定值分析实现,但是在trace中,可以认为语句之间是顺序执行的,ud链的构造只要向上遍历找到最后出现的对当前变量定值的语句即可。代码实现在VmProcedureCode类中的CopyPropagation和DeadCodeEliminatioin部分

图片3.png
在虚拟机的代码中,设定的活跃变量如下:
eax、ebx、ecx、edx、esi、edi、esp、eip、eflags寄存器esp+4,对应虚拟机退出后的跳转地址,去执行正常函数esp+8,正常函数执行完后的跳转地址,通常是虚拟机的入口esp+12,可能是正常函数的参数一esp+16,可能是正常函数的参数二esp+20,可能是正常函数的参数三esp+24,可能是正常函数的参数四esp+28,可能是正常函数的参数五esp+32,可能是正常函数的参数六以VmProcedureCode0.txt中的最后几行代码为例
0x0076591d: mov eax, dword ptr [0xffffcb5c]0x007e9342: mov dword ptr [0xffffcac8], eax0x006cbe8e: mov eax, dword ptr [0xffffcb34]0x006cbe9d: add eax, 0x77cb5a 0x0068849d: mov dword ptr [0xffffcad8], eax0x007df911: mov eax, dword ptr [0xffffcb34]0x007df919: add eax, 0x74fbf3 0x007df91b: mov dword ptr [0xffffcb60], eax 0x0068867f: mov eax, dword ptr [0xffffcb34] 0x00688684: add eax, 0x68304e 0x0068868a: mov dword ptr [0xffffcb5c], eax 0x007cf964: mov edx, dword ptr [0xffffcac8] 0x006ef09c: mov dword ptr [0xffffcb58], edx 0x006d717b: mov ebp, dword ptr [0xffffcad0] 0x006d717e: mov ecx, dword ptr [0xffffcac4] 0x006d7180: mov ebx, dword ptr [0xffffcaec] 0x006d7181: mov eax, dword ptr [0xffffcad8] 0x006d7185: mov edi, dword ptr [0xffffcae0] 0x006d7187: mov edx, dword ptr [0xffffcab8] 0x006d718d: mov esi, dword ptr [0xffffcac0] 0x006d718e: popfd最后一行的代码中esp=0xffffcb58,0x00688684地址处的0x68304e刚好对应虚拟机退出后的跳转地址,0x007df919地址处的0x74fbf3对应的是下一个虚拟机入口。0x006cbe9d地址处的 0x77cb5a 对应0x68304e函数的参数,ida中0x68304e地址处的代码反编译如下:
HMODULE __usercall GetModuleHandleA_68304E@<eax>(int a1@<eax>){ unsigned int v1; // edx int v2; // edi CHAR v3; // al CHAR ModuleName[260]; // [esp+0h] [ebp-104h] BYREF v1 = 0; v2 = a1 - (_DWORD)ModuleName; do { v3 = ModuleName[v1 + v2] ^ (v1 + __ROL4__(0x4BB06C51, v1)); ModuleName[v1] = v3; if ( !v3 ) break; ++v1; } while ( v1 < 0x104 ); return GetModuleHandleA_1(ModuleName);}程序切片技术
程序切片技术是为了替换之前使用的污点分析,方便获取handle中与写内存相关的指令。
给定一个感兴趣的语句以及它所使用的变量,程序切片(program slicing)是一个影响该条语句变量值的语句集合,而切片准则(slicing criterion)用来描述这个感兴趣的语句及其变量。切片准则可以定义为C = <statement, variables>,statement可以为语句的唯一序号,variables为变量集。比如有以下程序,令切片准则C=<10, {product}>,箭头左边为原程序,箭头右边为对应C的程序切片。
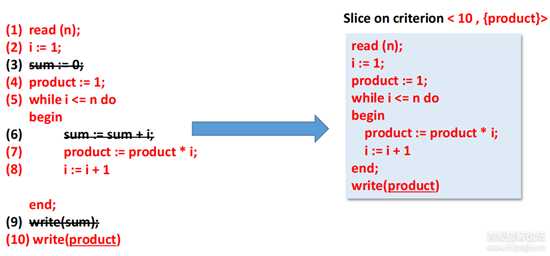
图片4.png
程序切片的实现主要有基于程序依赖图和基于数据流方程两种方法。程序依赖图包含数据依赖和控制依赖,它的构建可以查看鲸书等相关资料,这里只介绍基于数据流方程的方法。数据流方程迭代的公式如下:
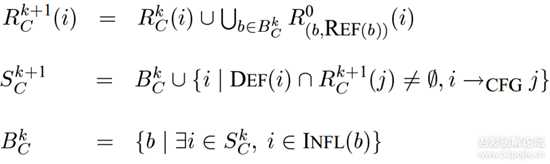
图片5.png
k表示迭代次数,如果把语句当做CFG中的一个结点而不是基本块的话,那么i和j就是一个语句,其中i是j的前驱结点。
DEF(i)和REG(i)分别表示i结点的变量定值集和引用集。
C和(b, REF(b))表示相应的切边准则。
B[k][C]是分支语句集,表示影响S[k][C]中切片语句的分支语句集合,用来跟踪控制依赖关系,迭代过程中当B[k][C]不在改变时,迭代终止。
INFL(b)表示从b开始到距离它最近的后向支配语句之间的路径上除去端点以外所有语句的集合,INFL(b)在其直接后驱大于等于2时才不为空,否则为空集。INFL(b)中的语句执行受b语句执行结果的影响,控制依赖于b。
R[k]C表示结点i中与切片准则C相关的变量集合,用来跟踪数据依赖。
S[k][C]表示程序切片。
初始化时,R[0]C等于切片准则C中的变量集variables,n为C中的statement,当n≠m时,R[0]C为空集。之后再从以下公式计算各个结点的R[0][C]和S[0][C]。
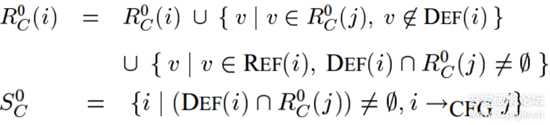
图片6.png
基于数据流方程的过程内切片伪算法如下:

图片7.png
由于vmp的handle代码是顺序执行,所以针对handle的切片处理不需要多轮迭代和控制依赖的跟踪,也就不需要计算INFL(b),相应的切片算法会变得很简单,只需要一轮迭代计算出R[0][C]和S[0][C]就可以得到对应的切片。
基于DAG有向无环图的局部优化
把基本块转换到DAG有向无环图的表示,在DAG上可以对基本块中的代码进行一些转换,改进代码的质量。
龙书中的关于DAG的构造方式如下:
1)基本块中出现的每个变量有一个对应的DAG的结点表示其初始值。
2)基本块中的每个语句s都有一个相关的结点N。N的子结点是基本块中的其他语句的对应结点。这些语句是在s之前、最后一个对s所使用的某个运算分量进行定值的语句。
3)结点N的标号是s中的运算符,同时还有一组变量被关联到N,表示s是在此基本块内最晚对这些变量进行定值的语句。
4)某些结点被指明为输出结点(output node),这些结点的变量在基本块的出口处活跃。也就是说,这些变量的值可能以后会在流图的另一个基本块中被使用到。计算得到这些“活跃变量”是全局数据流分析的问题。
针对vmp的trace主要做一些以下优化:
1、消除局部公共子表达式(local common subexpression),公共子表达式就是重复计算一个已经计算得到的值的指令。当一个新的结点M将被加入到DAG中时,我们检查是否存在一个结点N,它和M具有同样的运算符和子结点,且子结点顺序相同。如果存在这样的结点,N计算的值和M计算的值是一样的,可以用N替换M
2、常量折叠
3、使用代数规则简算计算过程,比如vmp中not、and和or等指令组合起来的MBA表达式
以VmProcedureCode0.txt中的前面103行代码为例
0x0064d71e: mov dword ptr [0xffffcfe8], ecx 0x006fa4c2: mov dword ptr [0xffffcf34], edx 0x00746037: mov dword ptr [0xffffcf3c], ebp 0x0064fb73: mov eax, 4 0x006b7076: add eax, 0xffffcff8 0x006b707f: mov dword ptr [0xffffcff4], eax 0x0075d399: mov eax, 8 0x0075d3a7: add eax, 0xffffcff4 0x0081c8fb: mov ecx, eax 0x0081c903: mov edx, dword ptr [0xffffcff4] 0x0081c906: not ecx 0x006e651b: not edx 0x006e651e: or ecx, edx 0x00750b99: mov eax, ecx 0x00750ba3: add eax, 0x20 0x00750bb2: pushfd 0x00750bba: pop dword ptr [0xffffcff4] 0x0077cd5f: mov ecx, dword ptr [0xffffcff4] 0x007294f8: mov dword ptr [0xffffcf18], ecx 0x007b85c7: mov ecx, eax 0x007b85d0: mov edx, eax 0x007b85d3: not ecx 0x007b85d6: not edx 0x007b85d8: or ecx, edx 0x007b85e0: pushfd 0x007b85e9: pop dword ptr [0xffffcff4] 0x00687ebb: mov ecx, dword ptr [0xffffcf18] 0x00687ebf: mov edx, dword ptr [0xffffcf18] 0x00674371: not ecx 0x0067437a: not edx 0x0067437f: or ecx, edx 0x00674383: mov dword ptr [0xffffcfd8], ecx 0x006a83d9: mov ecx, 0xfffff7ea 0x006a83df: mov edx, dword ptr [0xffffcfd8] 0x006a83e2: not ecx 0x006a83e4: not edx 0x006a83ed: and ecx, edx 0x006a83ef: mov dword ptr [0xffffcfd8], ecx 0x00809c7d: mov ecx, dword ptr [0xffffcff4] 0x00809c7f: mov edx, dword ptr [0xffffcff4] 0x00739b61: not ecx 0x00739b63: not edx 0x00739b65: or ecx, edx 0x00739b67: mov dword ptr [0xffffcfd4], ecx 0x00740510: mov ecx, 0x815 0x00740516: mov edx, dword ptr [0xffffcfd4] 0x00740519: not ecx 0x00740520: not edx 0x00740525: and ecx, edx 0x007f9eca: mov eax, ecx 0x007f9ed9: add eax, dword ptr [0xffffcfd8] 0x007bd4bc: mov dword ptr [0xffffcf50], 0 0x0070d7e7: mov dword ptr [0xffffcf20], ebx 0x00723792: mov dword ptr [0xffffcf14], eax 0x006f8562: mov dword ptr [0xffffcf44], esi 0x006d7d4c: mov ecx, dword ptr [0xffffcfe8] 0x006d7dab: mov dword ptr [0xffffcf28], ecx 0x007964f4: mov ecx, dword ptr [0xffffcf34] 0x0079653f: mov dword ptr [0xffffcf1c], ecx 0x007bdb9e: mov dword ptr [0xffffcf30], edi 0x0069f4d8: mov dword ptr [0xffffcf24], eax 0x007bd4bc: mov dword ptr [0xffffcf34], 0xffffcfd4 0x006f8529: mov ecx, dword ptr fs:[0] 0x006f8562: mov dword ptr [0xffffcf4c], ecx 0x0068a851: mov eax, 4 0x0068a867: add eax, 0xffffcfc0 0x0068a86e: mov dword ptr [0xffffcfbc], eax 0x007d8470: pushfd 0x007d8478: pop dword ptr [0xffffcfb8] 0x006d7d4c: mov ecx, dword ptr [0xffffcfb8] 0x006d7dab: mov dword ptr [0xffffcf48], ecx 0x007fb9d4: mov eax, 8 0x007fb9d9: add eax, 0xffffcfbc 0x007fb9ea: pushfd 0x007fb9eb: pop dword ptr [0xffffcfb4] 0x0067df7a: mov ecx, dword ptr [0xffffcfb4] 0x0067dfd4: mov dword ptr [0xffffcf2c], ecx 0x006a4226: mov ecx, dword ptr [0xffffcfbc] 0x006d370e: not eax 0x006d3710: not ecx 0x006d3712: or eax, ecx 0x006d3717: pushfd 0x006d3718: pop dword ptr [0xffffcfb8] 0x0077c25e: mov ecx, dword ptr [0xffffcfb8] 0x007e2e9f: mov dword ptr [0xffffcf38], ecx 0x00745a49: add eax, 0x454 0x00745a4e: pushfd 0x00745a4f: pop dword ptr [0xffffcfbc] 0x007964f4: mov ecx, dword ptr [0xffffcfbc] 0x0079653f: mov dword ptr [0xffffcf40], ecx 0x00697f01: mov edx, eax 0x00697f09: mov ecx, eax 0x00697f0d: not edx 0x00697f11: not ecx 0x00697f14: and edx, ecx 0x00813a43: pushfd 0x00813a4b: pop dword ptr [0xffffcfbc] 0x00764298: mov ecx, dword ptr [0xffffcfbc] 0x007bdb9e: mov dword ptr [0xffffcf18], ecx 0x00716b65: mov ecx, 0x40 0x0064c470: pushfd 0x00753bc8: mov esi, 0xffffcf14 0x00753bca: mov edi, 0xffffcab0DAG优化后的输出为
ds[0xffffcfe8] = ecxds[0xffffcf28] = ecxds[0xffffcf1c] = edxds[0xffffcf3c] = ebpds[0xffffcfd8] = 0x815 & eflags0_0ds[0xffffcff4] = eflags1_128ecx = 0xfffff7ea & eflags1_128ds[0xffffcf14] = ecx + ds[0xffffcfd8]ds[0xffffcf24] = ds[0xffffcf14]ds[0xffffcf50] = 0x0ds[0xffffcf20] = ebxds[0xffffcf44] = esids[0xffffcf30] = edids[0xffffcf34] = 0xffffcfd4ds[0xffffcf4c] = fs[0x00000000]ds[0xffffcf48] = eflags2_128ds[0xffffcfb4] = eflags3_144ds[0xffffcf2c] = eflags3_144ds[0xffffcfb8] = eflags4_0ds[0xffffcf38] = eflags4_0eax = 0x348fds[0xffffcf40] = eflags5_0edx = 0xffffcb70ds[0xffffcf10] = eflags6_128ds[0xffffcfbc] = eflags6_128ds[0xffffcf18] = eflags6_128ecx = 0x40ds[0xffffcaa4] = eflags7_128esi = 0xffffcf14edi = 0xffffcab0eflags7_128第一个数值7表示出现次数的编号,128为eflags寄存器的值。这里用到了一个化简规则:a = ~(~a | ~a),在化简前DAG的可视化如下:
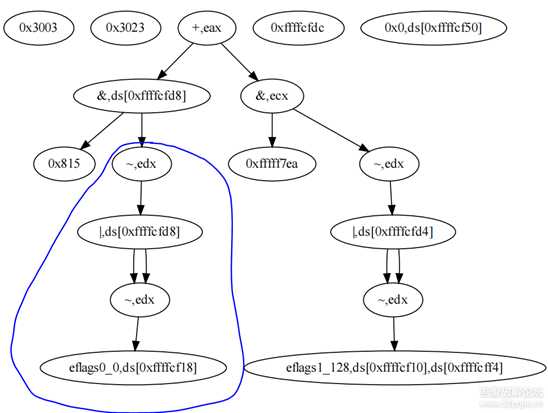
图片8.png
蓝色圈就对应a = ~(~a | ~a)的运算,那么可以直接使用a对应的结点代替这个蓝色圈
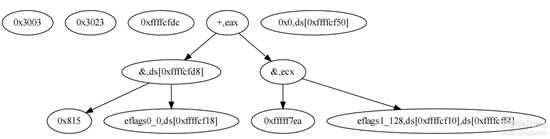
图片9.png
如果觉得赋值语句还是多的话,也可以利用DAG删除无用赋值。DAG的优化只支持部分x86指令,大家可以根据自己需要自行增减,代码的实现部分在DAGoptimizer类
图片10.png
参考资料
《编译器设计之路》
《编译原理》(龙书)
《高级编译器设计与实现》(鲸书)
基于程序分析与测试的二进制软件漏洞挖掘技术研究
WEISER M.Program Slicing[J].IEEE Transactions on Software Engineering,1984,SE-10(4):352--357.